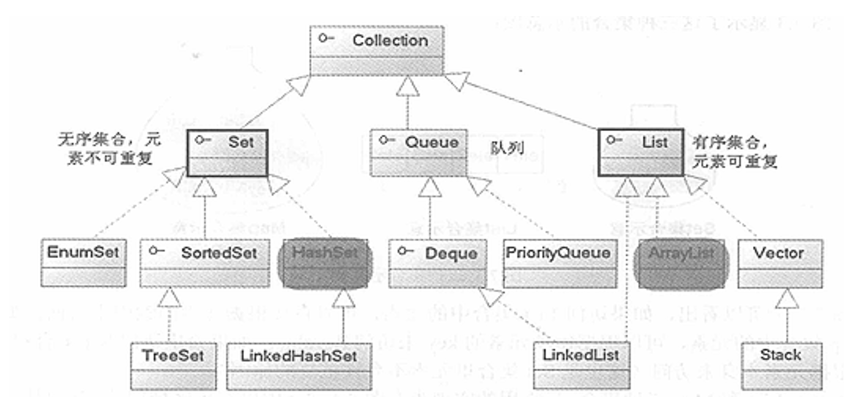
java集合类
继承关系图
- 从collection衍生出来的都是不含键值对的
- 分为 有序的List 无序的Set 队列Queue
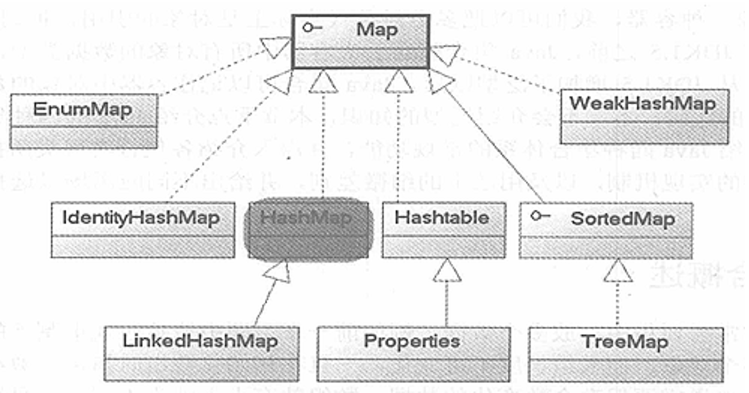
LinkedHashMap 数据结构
继承自HashMap,未重写get方法
用一个header维护一个双向链表,header本身为null,header.before指向最后一个添加的元素,header.after指向第一个添加的元素。例如顺序插入1 2 3 4,header如下
4-3-2-1(after)-header-4(before)header里面的元素 和 table里面的元素指向的是同一个元素,header里面的元素都是引用,而不是new一个相同的entry,节省内存空间
迭代的时候修改了规则,最开始取header的after元素也就是第一个插入的元素
private abstract class LinkedHashIterator<T> implements Iterator<T> {//第一个nextEntry 就是header.after 也就是第一个插入的元素Entry<K,V> nextEntry = header.after;Entry<K,V> lastReturned = null;重写了Entry(除了有next 给hashmap常规操作用,还有 before、after给header顺序读取用)其中before 和after记录的是插入的顺序的元素,next是在hashmap中同一个index下的下一个元素,after和next一般都不是指向同一个元素
插入有相同值时,元素在header中的顺序取的是第一次存储的位置
理论上也可以用一个数组来维护插入的顺序,可以更灵活的支持 get(3)
Hashtable 数据结构
和hashmap的区别:
历史原因:Hashtable是基于陈旧的Dictionary类的,HashMap是java 1.2引进的Map接口的一个现实。
同步性:Hashtable是同步的,这个类中的一些方法保证了Hashtable中的对象是线程安全的,而HashMap则是异步的,因此HashMap中的对象并不是线程安全的,因为同步的要求会影响执行的效率,所以如果你不需要线程安全的结合那么使用HashMap是一个很好的选择,这样可以避免由于同步带来的不必要的性能开销,从而提高效率,我们一般所编写的程序都是异步的,但如果是服务器端的代码除外。
值:HashMap可以让你将空值作为一个表的条目的key或valueHashtable是不能放入空值(null)的
下图所示 put get size remove方法都是加锁的
ArrayList 数据结构
特点
- 线性不安全,异步效率高,线性安全要用Vector
- 默认大小给的是10,如果扩容的话,大小约为1.5倍,是指向新的一个对象而不是原list变长。
大的list的话,可以通过给定init大小来初始化list的长度。 - 插入 和删除 会根据下标 移动下标后续的元素。
注意事项
为了提高插入的效率,new的时候指定大小可以节省内存空间和插入的效率,避免resize的发生
Vector 数据结构
和ArrayList 相比,在JDK1.7中有一个包含capacityIncrement参数的构造函数,可以指定resize的时候扩容的大小,如果不指定的话,默认resize的时候翻倍,而ArrayList则是50%扩容
public Vector(int initialCapacity, int capacityIncrement) {线程安全的,操作都是加锁的,操作和 ArrayList 差不多
HashSet 数据结构
- 可以去重,因为基于hashmap,把值作为key插到hashmap中
- 常数级别的查找(其实一般contains方法会用到的查找),和数组相比不是一个量级的
- 迭代就是hashmap的 keyIterator()
LinkedList
最大的特点是灵活,支持各种API。不支持随机访问,查找还是慢的,要从first结点 挨个遍历,在API里面是 contains(object o)函数来实现
- 链表是双向的,并且由first结点和last结点连成一个线段
顺序插入 1 2 3 4 –> null-4-3-2-1-null 结点Node构造如下
private static class Node<E> {E item;Node<E> next;Node<E> prev;}默认的add方法是向链表 尾部追加,但是支持各种灵活的操作,getFirst() addFirst()getLast() addLast(),所以可以实现 队列和栈结构
支持顺序插入 add(index,Item) set(index,item)
concurrentHashMap
有待添加,阿里面试喜欢问这个
