HashMap数据结构
解决的问题
实现常数级别的查找和插入
依赖:
- 好的散列算法使元素分布均匀
- loadfactor不是特别大使结构更像一个数组
- 对于计算机来说友好的(开销小)的散列运算方法(因为所有的查找都要先进行散列运算)
结构特点
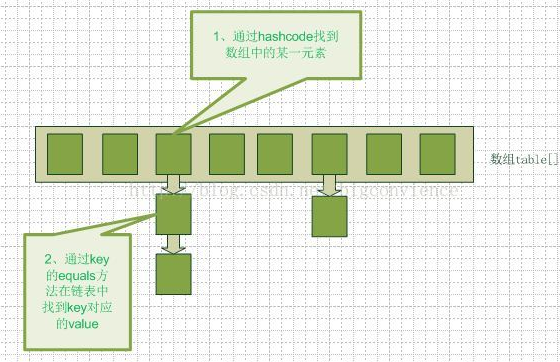
- 结合了数组结构(查询快)和链表结构(插入和删除快1)的特点。
- 基于拉链法的结构(相对于线性探测法来说,更高效的支持删除元素,以及更好的利用内存空间,因为拉链法可以使用非连续的内存空间,同时查找和插入的性能差不多,都是常数级别的查找和插入)
- 具有动态的扩展性,插入的元素到增多的时候可以resize(),节省内存空间的同时又能随着元素数量做到动态调整
- 线性不安全,需要线性安全的话需要用 Hashtable
第一层是数组 Entry(K,V) 的一个数组 table,根据key的hashcode值,对当前数组长度-1进行 &运算,得出该键值对 在数组中的存储位置。然后再判断 数组的该位置是否有值,如果该数组位置没有值(null),那么这个键值对的位置就是入住。如果该数组位置有值,那么老主人 就作为新主人的一部分,新进来的键值对占据该位置, Entry current.next= oldEntry. 也就形成了链表的结构,上线找下线,下线下面可能还有下线也有可能没有
使用的注意事项
1)合理的设置loadfactor的大小,设置的越小,占用的连续内存越多,如果初始化size设置的不对的话,会频繁的resize,从而影响插入的性能,
但是大幅提升查询和不resize()插入的效率,因为冲突的概率更低
2)合理设置initSize的大小,initSize=实际Size/LoadFactor,这样可以避免resize的发生。
数组的长度
初始化的时候是16( 2的4次方),每次扩容都是 2的N次方
|
为什么取2的N次方,因为 在键值对插入的时候,会对index求hashcode值,然后将hashcode值和 数组长度-1 进行 &运算(后面会重点讲 &运算)
|
&运算
就是把前后2个值转换为 2进制,相同位置上都为1 则为1,其他的都为0
例如左边图是 16长度数组,也就是 9&15 8&15 运算结果,一个1001(9 十进制) table[9]的位置, 一个1000(8 十进制)table[8]的位置
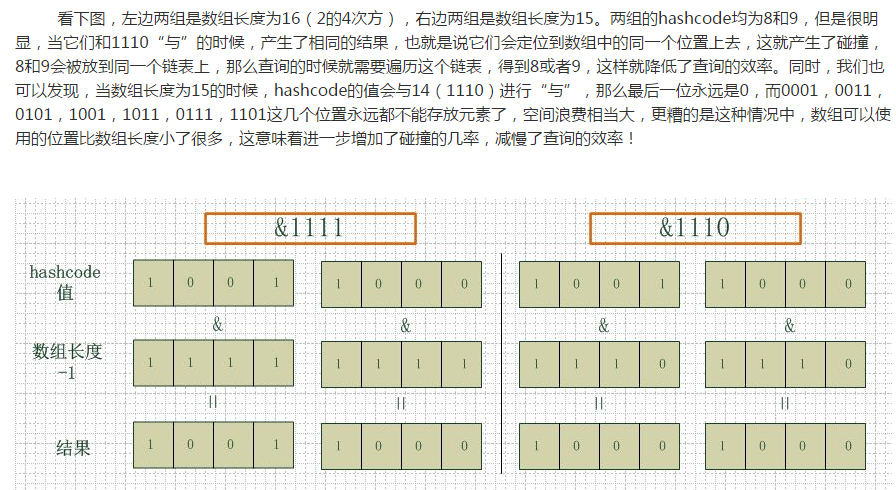
如果不是2的N次方,那么总数-1 转换为2进制的时候,肯定有一个位置上为0
例如如果数组长度为15,那么 N-1=14, 14转换为二进制就是 1110
进行&运算的时候,因为1110与任何数进行&运算的结果都不可能是 *1,所以例如 0001 也就是 table[1]这个位置上始终都不可能有键值对可以插入进去,所以数组的长度只能是2的N次方。
resize的时机
- 当size达到 length的时候,必然触发
- size>=0.75length 和 table[index]!=null。也就是当size超过0.75length的时候就有概率触发扩容,而且这种触发是随机的。
loadFactor的设置
当然也可以根据实际的需求设置 loadFactor,来设置适合业务规则的 hashmap。
如果内存富余,那么建议把loadFactor设置的小一点,但是要注意 初始size的设置,如果不合适会导致频繁的 resize 严重影响插入的效率。
如果内存比较吃紧,就可以把loadFactor设置的大一些,但是loadFactor设置大的话,键值对以链表的形式存储的概率就提高,平均的查询时间变慢,但是对于插入而言,虽然没有直接的影响,但是loadFactor提高,
需要插入更多的数据才会触发 resize,这样某种程度上是提升了 插入的效率
插入到某个有值的位置,挨个对比是否有 key值相同的对象
2.4.1)如果有key值一样(hashcode值相同,而且key==oldKey|| key.equals(k)),则替换并返回老的key的value值
2.4.2)如果没有key值一样的,那么该位置会被最后一个进来的Entry 占据,并且Entry的next属性,指向 之前第一个位置的Entry,也就是链表了,一个找一个
|
初始化hashmap 2种 构造函数,
|
初始化hashmap length的设置
如果不修改 loadFactor的话(默认0.75),那么初始化的length应该为 1.34*size,比如1万个键值对,那么初始化的时候长度给13400比较合适,不会导致resize(),当然也要结合实际的内存情况做权衡
数据的put(插入一个元素)
3.1)key=null
会直接放在数组的table[0]位置
3.2)插入的位置没有值
直接返回null
3.3)插入的位置已经有值了
3.31)遍历该key是否存在
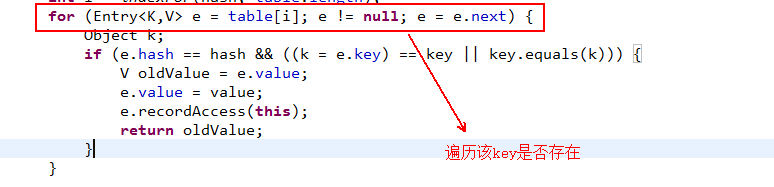
判断该key是否已经存在有2个条件 &&,hashcode值相同 并且 equals为true,一般实际开发不太可能出现这种情况,除非自己故意设置成这样。
hashmap的重构 resize()
会遍历之前所有的 Entry
计算新的 table.index
— 如果该Entry的 next不为空,则next占据原位置,并且下一个处理这个next
—- 如果待插入的位置已经有Entry,则按照之前的规则,把老的Entry 作为 next存在新的 Entry里面。
|
遍历
使用迭代器遍历(最优)
相对于下面这种方法,此方法更高效,挨个的首位获取元素,再输出值,第二种方法相当于遍历了一次hashmap的key值,然后,根据key值找value。Map map = new HashMap();Iterator iter = map.entrySet().iterator();while (iter.hasNext()) {Map.Entry entry = (Map.Entry) iter.next();Object key = entry.getKey();Object val = entry.getValue();}```- 使用增强for循环遍历,因为hashmap封装了 entrySet()方法Map
for (Entryentry.getKey(); entry.getValue();}
# JDK1.7 和JDK1.8中HashMap的数据结构调整1. JDK1.7是数组+单向链表的数据结构,缺点是当该HashMap的容量很大时,有概率会造成长链表,因为触发resize()函数的必要添加之一是3/4的size。此时查询和插入的时间复杂度是 O(N)。2. JDK 1.8中优化- 解决了链表过长该问题,当某个链表达到阈值的时候,就把该链表转换成红黑树,从而提升查询和插入的效率,设置了TREEIFY_THRESHOLD(触发树形转换,默认为8)、UNTREEIFY_THRESHOLD(触发链表转换,默认为6),转换为树形结构之后,查询的时间复杂度为 O(logN)了- resize的时机发生改变,当size>阈值时直接resize,而无需判断是否哈希冲突
if (++size > threshold)
resize();
int i = indexFor(hash, table.length);
entry=table[i]
entry!=null;
```
